
Classification
Bienvenue dans le module de formation sur les jeux de données !
Nous avons déjà étudié de nombreuses images satellite, souvent riches en végétation, mais comment déterminer précisément l'étendue de la couverture terrestre d'une région ? Les algorithmes de classification sont la solution !
Dans ce module, nous plongerons dans le monde passionnant de la classification et apprendrons à l'automatiser grâce aux techniques d'apprentissage automatique. En important une image et en collectant des points d'entraînement, nous pouvons entraîner un classificateur qui nous aidera à identifier différents types de couverture terrestre. Et le meilleur ? Nous pouvons appliquer ce classificateur à l'image entière et créer une magnifique carte mettant en valeur la diversité du paysage.
“Si vous entraînez les robots comme des chiens, ils apprennent plus vite.”
Classification avancée (ensembles de données d'entraînement)
La classification dans Google Earth Engine (GEE) fait référence au processus d'attribution de catégories de couverture ou d'utilisation du sol à différentes zones géographiques. L'objectif de la classification est de regrouper les pixels qui ont des propriétés ou des attributs spectraux similaires dans des catégories significatives.
Cela est utile pour une variété d'applications, notamment la cartographie de la couverture terrestre, la détection des changements et l'analyse des habitats. Il peut également être utilisé pour créer des cartes thématiques qui montrent la répartition des différentes classes de couverture terrestre dans une région, ce qui peut être utile pour la gestion des ressources naturelles et la planification de la conservation. La classification est effectuée à l'aide de techniques d'apprentissage automatique.
Arrière-plan
La classification supervisée utilise un ensemble de données d'apprentissage avec des étiquettes connues et représentant les caractéristiques spectrales de chaque classe de couverture terrestre d'intérêt pour « superviser » la classification. L'approche globale d'une classification supervisée dans Earth Engine se résume comme suit :
Obtenez une scène.
Collectez des données d'apprentissage.
Sélectionnez et entraînez un classificateur à l'aide des données d'apprentissage.
Classez l'image à l'aide du classificateur sélectionné (une méthode de pointer-cliquer super simple !)
Exercice
Nous utiliserons le code suivant pour créer un ensemble de données de formation qui sera utilisé pour classer de manière autonome le terrain autour de Rio de Janeiro, au Brésil.
// create an Earth engine point object over rio
var pt = ee.Geometry.Point([-43.173732,-22.903846])
// Filter the landsat 8 collection and select the least cloudy image
var landsat = ee.ImageCollection('LANDSAT/LC08/C02/T1_L2')
.filterBounds(pt)
.filterDate('2019-01-01','2020-01-01')
.sort('CLOUD_COVER')
.first()
//center the map on that image
Map.centerObject(landsat,8)
//Add Landsat image to the map
var visParams = {
bands: ['SR_B4','SR_B3','SR_B2'],
min: 7000,
max: 12000
};
Map.addLayer(landsat, visParams, 'Landsat 8 image');
À l'aide des outils de géométrie, nous allons créer des points sur l'image Landsat représentant les classes d'occupation du sol qui nous intéressent et qui serviront de données d'entraînement. Deux opérations sont nécessaires : (1) identifier l'emplacement de chaque occupation du sol sur le terrain ; (2) attribuer aux points le numéro de classe approprié. Pour cet exercice, nous utiliserons les classes et les codes présentés dans le tableau suivant.

Dans les outils de géométrie, cliquez sur l'option marqueur. Cela créera une géométrie de point qui s'affichera comme une importation nommée « géométrie ». Cliquez sur l'icône d'engrenage pour configurer cette importation.
Nous allons commencer par collecter des points de forêt, nommez donc l'importation forest. Importez-la en tant que FeatureCollection, puis cliquez sur + Property. Nommez la nouvelle propriété « class » et donnez-lui une valeur de 0. Nous pouvons également choisir une couleur pour représenter cette classe. Pour une classe de forêt, il est naturel de choisir une couleur verte. À l'avenir, vous pourrez simplement choisir la couleur, mais pour cet exemple, entrez le code de couleur hexadécimal spécifique #589400.
Maintenant, dans les importations de géométrie, nous verrons que l'importation a été renommée forest. Cliquez dessus pour activer le mode dessin afin de commencer à collecter des points de forêt.

Commencez maintenant à collecter des points sur les zones forestières. Effectuez des zooms avant et arrière selon vos besoins. Vous pouvez utiliser la carte satellite, mais l'image Landsat doit constituer la base de votre collecte. N'oubliez pas que plus vous collectez de points, plus le classificateur apprendra des informations que vous lui fournissez. Pour l'instant, fixons-nous un objectif de 25 points par classe. Cliquez sur « Quitter » à côté de « Dessin de points » une fois terminé.
Répétez le même processus pour les autres classes en créant de nouvelles couches. N'oubliez pas d'importer avec l'option « FeatureCollection » comme indiqué ci-dessus. Pour la classe développée, collectez des points sur les zones urbaines. Pour la classe aquatique, collectez des points sur l'océan et les autres plans d'eau. Pour la classe herbacée, collectez des points sur les champs agricoles. N'oubliez pas de définir la propriété « class » de chaque classe sur le code correspondant du tableau, puis cliquez sur « Quitter » une fois la collecte de points pour chaque classe terminée, comme indiqué ci-dessus. Nous utiliserons les couleurs hexadécimales suivantes pour les autres classes : #FF0000 pour « développé », #1A11FF pour « eau » et #D0741E pour « herbacée ».
Vos données d'entraînement pourraient ressembler à ceci :
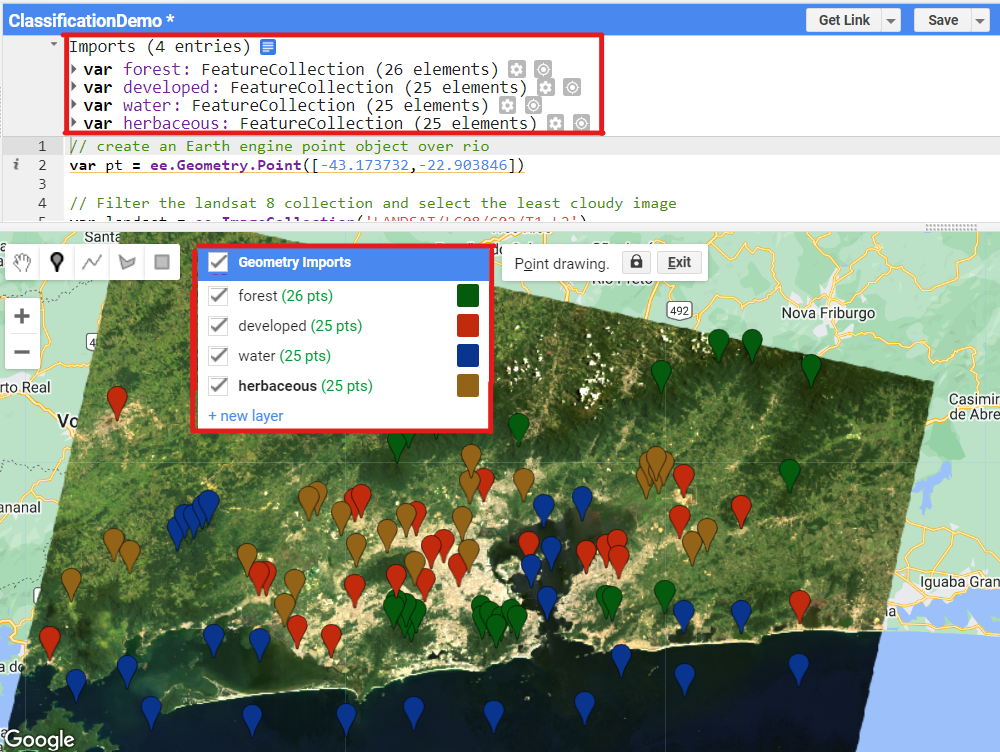
Vous devriez maintenant avoir quatre importations FeatureCollection nommées forêt, développé, eau et herbacé.
L'étape suivante consiste à combiner toutes les collections de fonctionnalités d'entraînement en une seule. Copiez et collez le code ci-dessous pour les combiner en une seule FeatureCollection appelée trainingFeatures. Ici, nous utilisons la méthode flatten pour éviter d'avoir une collection de collections de fonctionnalités : nous voulons des fonctionnalités individuelles dans notre FeatureCollection.
// training begins var trainingFeatures = ee.FeatureCollection([ forest, developed, water, herbaceous ]).flatten();
Maintenant que nous disposons de nos points d'entraînement, copiez-collez le code ci-dessous pour extraire les informations de bande pour chaque classe à chaque point. Nous définissons d'abord les bandes de prédiction afin d'extraire différentes informations spectrales et thermiques de chaque bande pour chaque classe. Ensuite, nous utilisons la méthode sampleRegions pour échantillonner les informations de l'image Landsat à chaque point. Cette méthode nécessite des informations sur la FeatureCollection (nos points de référence), la propriété à extraire (« classe ») et l'échelle de pixel (en mètres).
// Define prediction bands
var predictionBands = ['SR_B1','SR_B2','SR_B3','SR_B4','SR_B5','SR_B6','SR_B7','ST_B10'
];
//Sample training points
var classifierTraining = landsat.select(predictionBands)
.sampleRegions({
collection: trainingFeatures,
properties: ['class'],
scale: 30
});
Il est maintenant temps de choisir une méthode de classification. Il s'agit d'algorithmes qui utilisent vos données d'entraînement pour classer automatiquement l'ensemble du terrain de la zone souhaitée (apprentissage automatique !). L'un des algorithmes les plus courants est le classificateur CART (Classification and Regression Tree). Utilisez le code ci-dessous pour implémenter le classificateur CART.
// Train a CART classifier
var classifier = ee.Classifier.smileCart().train({
features: classifierTraining,
classProperty: 'class',
inputProperties: predictionBands
})
Maintenant que vous avez formé le classificateur, utilisez simplement le code ci-dessous pour classer l’image Landsat et l’ajouter à la carte.
// Classify the landsat image
var classified = landsat.select(predictionBands).classify(classifier);
// Define classification image visualization parameters
var classificationVis = {
min: 0,
max: 3,
palette: ['589400','ff0000','1a11ff','d0741e']
};
// Add the classified image to the map
Map.addLayer(classified, classificationVis, 'CART classified')
Ouf ! On vient d'apprendre beaucoup ! Ralentissez, examinez le code ligne par ligne et réfléchissez à la fonction de chaque fragment. En résumé :
Nous avons importé une image LANDSAT, puis filtrée par date et lieu. Nous avons ensuite ajouté cette image comme calque à la carte.
Nous avons créé des géométries de points à utiliser comme points d'entraînement pour notre algorithme de classification (en utilisant une simple technique de pointer-cliquer !).
Nous avons ajouté ces points d'entraînement à une variable appelée trainingFeatures, puis ajouté des bandes à notre variable predicitonBands pour notre classificateur.
Nous avons utilisé ces variables comme entrées pour entraîner notre classificateur CART.
Notre classificateur est maintenant entraîné ; nous l'avons donc utilisé pour classer automatiquement le reste de notre image et afficher les résultats !
Résultats
Inspectez le résultat : activez la couche composite Landsat et le fond de carte satellite pour les superposer aux images classées. Modifiez la transparence des couches pour inspecter certaines zones. Que remarquez-vous ? Le résultat peut ne pas être très satisfaisant dans certaines zones (par exemple, confusion entre les classes développées et herbacées). À votre avis, pourquoi cela se produit-il ?
Voici quelques façons dont nous pouvons améliorer notre code de classification :
Recueillir plus de données de formation: Nous pouvons essayer d’incorporer plus de points pour avoir un échantillon plus représentatif des classes.
Essayez d’autres classificateurs : Si les résultats d’un classificateur ne sont pas satisfaisants, nous pouvons essayer certains des autres classificateurs d’Earth Engine pour voir si le résultat est meilleur ou différent.
Élargir l'emplacement de la collecte : Il est recommandé de collecter des points sur l'ensemble de l'image et de ne pas se concentrer sur un seul emplacement. Recherchez également les pixels d'une même classe qui présentent une variabilité (par exemple, pour la classe développée, les toits des bâtiments sont différents de ceux des maisons ; pour la classe herbacée, les champs cultivés présentent une saisonnalité/phénologie distincte).
Ajouter plus de prédicteurs : Nous pouvons essayer d'ajouter des indices spectraux aux variables d'entrée ; de cette façon, nous fournissons au classificateur de nouvelles informations uniques sur chaque classe. Par exemple, il y a de fortes chances qu'un indice de végétation spécialisé dans la détection de la santé de la végétation (par exemple, NDVI) améliore la classification des espèces développées par rapport aux espèces herbacées.
Résumer
Cette formation était très complète.
Voici ce que nous avons appris :
Les algorithmes de classification sont utiles pour déterminer l'occupation du sol et la gestion des ressources d'une région, et peuvent être automatisés grâce au machine learning !
Il suffit d'importer une image, de collecter des points d'entraînement, d'entraîner le classificateur, puis d'appliquer le classificateur entraîné au reste de l'image.
Nouveaux éléments de code :
Vous trouverez ici une multitude de nouveaux éléments de code. Ce code est idéal à copier-coller, puis à modifier selon vos besoins pour votre application. Ajoutez ou supprimez des classes ! Modifiez les couleurs si vous le souhaitez. Soyez créatif pour classer de nouveaux éléments pertinents pour votre application.